1차적으로 다크웹 크롤러가 완성되었습니다. !!
(완성은 옛날에 했지만 글은 지금씁니다. 선 개발, 후 리포트 ㅋㅋ)
생각보다 잘 작동하는것 같습니다.
Q 무엇을
.onion 크롤러를 만들었습니다. (데이터 수집), 수집한 데이터를 보여주는 웹도 만들었습니다.
Q 어떻게
Python3 + tor 등을 이용해서 만들었습니다. (자세한 python3 모듈은 코드 참고)
ubuntu(16) server 2개를 사용했습니다. 크롤러 1개 데이터 저장 1개
Q 왜
bunseokbot선배가 토르 크롤러 엔진을 개발했는데, 보다 보니 흥미가 생겨서 엔진은 아닌 단순 크롤러 코드를 작성해봤습니다.
output


탐지에 관한 간략한 설명
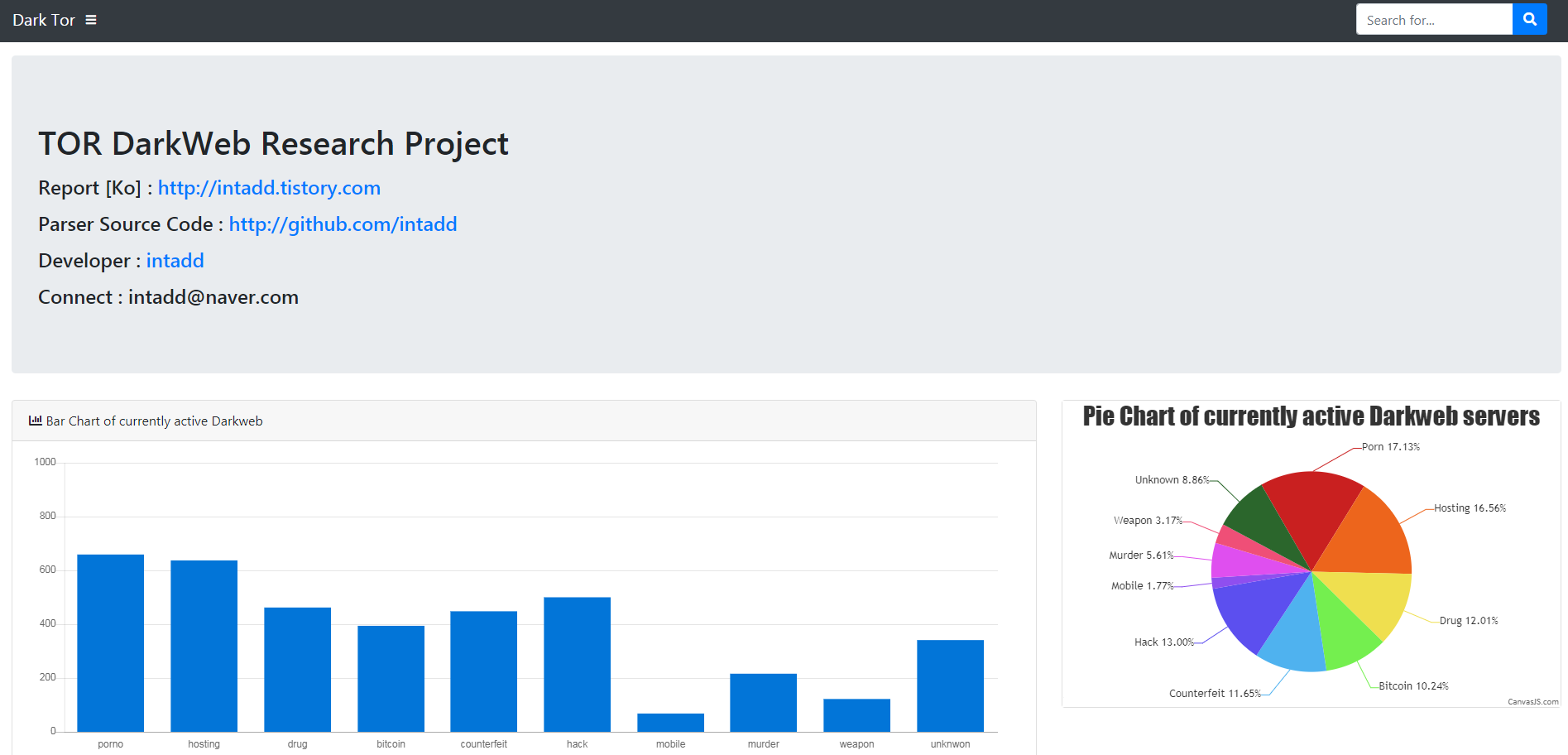
탐지 방법은 키워드 기반의 탐지입니다.
'음란물, 호스팅, 해킹, 마약, 비트코인, 위변조, 모바일, 살인, 무기'를 기준으로 카테고라이징 했습니다.
가장 먼저 한 것 . 위의 9가지 카테고리의 관련 단어를 수집했습니다. (영어)
마약 - 마약 이름1,마약 이름2, 관련단어 등등
호스팅 - 서버, ram, 관련단어 등등
....
관련 단어를 일일이 수집하기 힘들기 때문에 relatedwords.org 를 이용하면 됩니다.
Parsing 할 때는 https://relatedwords.org/api/related?term=[word]
반환 값이 dict 형태이고 얼마나 연관되어 있는지까지 정보(score)를 제공하기 때문에
Score를 통해 관련성을 높일 수 있었습니다.
(혹시 모르니, 결과 값들은 연관단어가 맞는지 확인이 필요합니다.)
간단하게 작성한 relatedwords.org parsing 코드 + 실행화면


(라인이 15줄 + 코드 복사 귀찮아서 캡처한 정성)
두 번째 키워드들의 언어팩을 만듭니다.
사이트 자체가 영어가 아닌 다른 언어로 구성되어있을 수 있기 때문에 한국어, 중국어, 일본어, 러시아어 등등의 언어팩을 만들기로 했습니다.
저는 papago.naver.com 을 분석? 해서 간단하게 api를 짜면 쉽게 언어팩을 만들 수 있습니다.
(이 코드는 공개 X)
위와 같은 방법으로 탐지 키워드들을 구성했습니다.
번역이 잘 안된 것들도 있지만 그냥 진행했습니다.

세 번째 토르 네트워크에서 파씽할 데이터를 어디서 가져올지 고민하기 (데이터 수집 경로)
저는 토르 네트워크에 존재하는 검색엔진을 이용했습니다.
torSearch, ahmia 등등의 검색엔진을 파씽하여 원하는 카테고리를 검색한 뒤, 결과들을 종합하여
첫 수집 데이터로 사용했습니다.
(검색엔진을 분석한다 == 파씽을 하기 위해 분석한다.)
기타 등등
그 다음은 수집한 URL 들에서 다른 URL들을 찾아내고 request를 보낸 후 상태코드, header, html 코드를 가져온다.
이후 언어를 분석하는 모듈에 넣어주고, 언어에 맞는 정규식(언어팩)을 통해 카테고라이징한다. html 코드속 <title> 태그를 먼저 확인 한 후 정규식에 해당하지 않으면 html 코드 중 텍스트만 추출하여 한번 더 검사한다.
카테고리 + 키워드 탐지 +언어

소스코드
https://github.com/intadd/Darkup
intadd/Darkup
Onion Dark web Cralwer. Contribute to intadd/Darkup development by creating an account on GitHub.
github.com
끝.
후기 및 생각
그냥 가볍게 시작한 플젝이라 즐기면서 할려고 했지만,
즐기기에는 어려운 점이 많았다.
세상에는 혼종이 많다.
(정신 적으로 좀 아팠음)
공부 얘기 부터 하자면,
삽질도 많이하고 개인적으로 진짜 재미있었던 플젝이었습니다.
python 으로 tor 프록시 타는법 (requests, 소켓등)은 앞으로 유용하게 사용할것 같습니다.
개발 진행하면서 만났던 문제들
1. 크롤링을 안당할려고 한건지.. 아니면 어떠한 이유로 그렇게 개발한지는 모르겠으나.
소스코드가 일부분 인코딩 되어 있었다.
형식을 완전히 맞춘 인코딩도 아니었다
예를들어
'가나다' --> '가\uxxx\uxxx' 이런 식으로 한글자 혹은 두글자만 인코딩 되어 있었다.
이게 html 라인 1개당 1~2개 정도는 있었다.
이 문제가 왜 문제가 되냐면, txt 읽어서 언어확인하는 모듈로 가면
모듈이 에러를 토하면서 왜 이런 쓰레기를 넣었냐고 화를 내고 욕을 하기 때문이다.
때문에 정규식으로 제거했다. 제거 + .decode(errors="ignore")
2. TCP 소켓 Port 의 자원
이 문제는 정말 상상도 못했다.
일반적으로 파써 및 크롤러을 만들 때 전혀 만나보지 못한 에러였고,
에러 내용으로 port 자원 문제라고 유추하는 것도 어려웠다.
에러를 캡처를 못해놔서 어떤 에러인지 정확히는 기억이 안나는데
대충 connection pool 이였던것 같다.
requests를 요청할 때 tor network으로 연결을 한다.
이때 TCP를 통해서 proxy 연결을 하는데 연속해서 많은 요청을 하다보니까
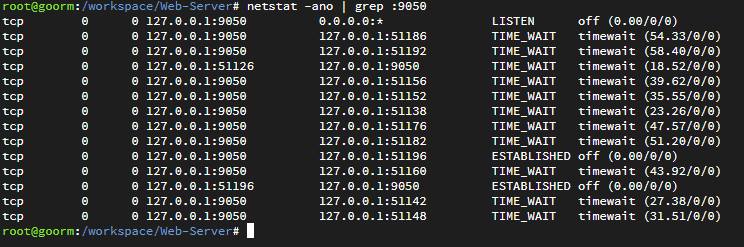
이러한 상태로 되어 버렸다. (TIME_WAIT)
9050은 토르 porxy 포트
이것은 TCP port 자원을 변경해 주거나 time wait 주기 변경 혹은 재사용 등을 설정하면 되는데,
구글에 검색하면 잘 나온다.
TCP time wait 라고 검색하면 쉽게 해결 할 것이다. (방법은 몇개 안되는데 잘 읽어보고 해결하면 될 것 같다)

나는 이렇게 해결을 한 것같다.
3. 카테고라이징이 안되는 문제
이건 아직 해결을 못했고, 해결이 안될 것 같다. 어찌 보면, 키워드 기반의 한계라고 생각한다.
내가 분류한 카테고리중 redroom 이라는 카테고리가 있는데 tor 네트워크에서는 잔인한? 좀 징그러운?
자료들을 올리고 공유하는 곳이다.
redroom 은 일단 검색엔진을 통해 찾기도 힘들고 코드가 다른 애들과는 약간 다르다.
소스코드 내에 text로 redroom 관련 단어를 찾기 힘들다.
redroom 사이트는 공개적으로 사이트를 이용하게 하지 않고, 비트코인을 받고 회원가입한 사람들에게만 계정을 준다.
그렇다 보니 로그인 창 + 계정 생성법만 text로 되어 있는 것들은 탐지가 안된다.
redroom 에 관련된 단어를(text) 사용하지 않고도 이 사이트가 redroom 이라는 것을 표현하는 방법은 많기 때문에,
탐색하기 어렵다.
예를 들어
background img src='//XXXX.onion?filehash=[filehash]'
이렇게만 만들어 놓으면 탐지를 못한다.
다른 방법을 통해 탐지하면 탐지가 되겠지만. 일단 키워드 기반에서는 힘들 것 같다.
------
약 만개 정도의 서버를 수집했고, 추가적으로 수집할 계획은 없다.
만개의 데이터도 다 공개하는 것이 아닌 각각의 카테고리 별로 몇개만 공개하고 있다. 총(120? 110?).
데이터를 수집하고 보면, 정신적으로 아픈 데이터가 많다. 정말로..
데이터를 모두 공개 안하는 이유도 이런 이유 때문이다.
'개발' 카테고리의 다른 글
| DarkWeb Research [0] (0) | 2019.02.10 |
|---|---|
| python 파씽 requests,BeautifulSoup (1) | 2017.09.13 |

댓글